

HDF5 Plugin for ImageJ and Fiji
HDF5 is a data format for storing extremely large and complex data collections. For more information see the official website http://hdf.ncsa.uiuc.edu/HDF5/. The plugin uses the jhdf5 library from ETH SIS for reading and writing HDF5 files.
Features
The HDF5 plugin for ImageJ and Fiji provides The following features:
- Loading 2D - 5D datasets
- Loading and combining mulitple 2d/3D datasets to 3D/4D/5D Hyperstacks
- Writing Hyperstacks to multiple 3D datasets
- scriptable load and save commands
Change Log
- Version 2014-08-27:
- Now displays "element size [um]" in load dialog
- Version 2014-08-22:
- Complete rewrite of the plugin. Now based on the jhdf5 library from ETH SIS
- older versions of this plugin.
Requirements
- ImageJ, plugins tested with Version 1.38 and newer. Or Fiji
- Linux, Mac OS X, or Windows, 32bit or 64bit
Download and Install
For ImageJ: Download the plugin and the jhdf5 library and put both files into the plugin-folder of your ImageJ installation
- HDF5_Vibez.jar (version 2014-08-27)
- cisd-jhdf5-batteries_included_lin_win_mac.jar (version SNAPSHOT-r30323 from Bernd Rinn from 29.12.2013)
For Fiji:
- Click on "Help--Update..." (the last entry in the help-menu) and wait until the popup appears
- Click on the "Manage update sites" button
- Enable the "HDF5" update site, and click the "Close" button
- Click the "Apply changes" button to install the plugin
- Restart Fiji
Updgrading from an older version. If you have an older version of this plugin installed. Please delete all files (esp. the platform dependend libraries), before installing the new one.
Example Data Sets
- pollen.h5 (3D confocal data of a pollen grain: 8 bit gray, approx. 16MB
- e098.h5 3D confocal raw data of a zebrafish embryo from our ViBE-Z project: 2 channels, 2 tiles, 2 laserintensities, and 2 recording directions, 8 bit gray, approx. 477MB)
- ViBE-Z_72hpf_v1.h5 Aligned Gene expression patterns from our ViBE-Z project: 8 bit gray, 4 anatomical chanels and 16 pattern channels., approx. 218MB
Usage
Load data sets
- Select "File -- Import -- HDF5...". The file selector will pop up. Double click the file you want to load.
- The "Select data sets" dialog will open:
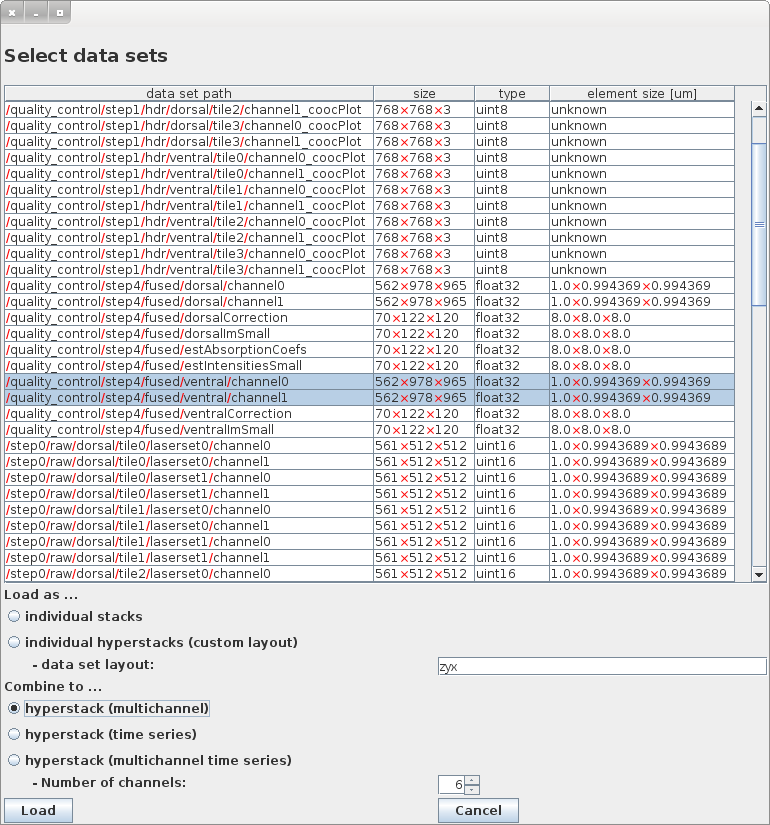
- select one or more datasets. Multiple selections can be done by
- mouseclick on first and Shift+mouseclick on last item
- mousedown on first and drag to last item
- CTRL+mouseclick to select / deselect individual items
- CTRL+A selects all items
- chose how they should be loaded or combined to a hyperstack.
- Load as ... individual stacks will create an individual window for each selected data set
- Load as ... individual hyperstacks (custom layout) will create a new hyperstack for each selected dataset. The data set layout has to be specified in the textfield below. HDF5 uses C-style / Java-style indexing of the array, i.e., the slowest changing dimension comes first (see size in the table). Typical storage orders are:
- "yx": 2D image
- "zyx": 3D image
- "tyx": 2D movie
- "tzyx": 3D movie
- "cyx": 2D multi-channel image
- "tczyx": 3D multi-channel move
- ...
- Combine to ... hyperstack (multichannel) loads the selected 2D/3D data sets and combines them to a multi-channel hyperstack
- Combine to ... hyperstack (time series) loads the selected 2D/3D data sets and combines them to a time-series hyperstack
- Combine to ... hyperstack (multichannel time series) loads the selected 2D/3D data sets and combines them to a multichannel time-series hyperstack. You have to specify the Number of channels of the resulting hyperstack. The number of time points is then determined from the number of selected data sets divided by the number of channels
Save data sets
- Select "File -- Save As -- HDF5 (new or replace)..." to create a new HDF5 file or "File -- Save As -- HDF5 (append)..." to append the dataset(s) to an existing HDF5 file. The file selector will pop up. Select the file name.
- The Save Dialog will open to select the data set layout
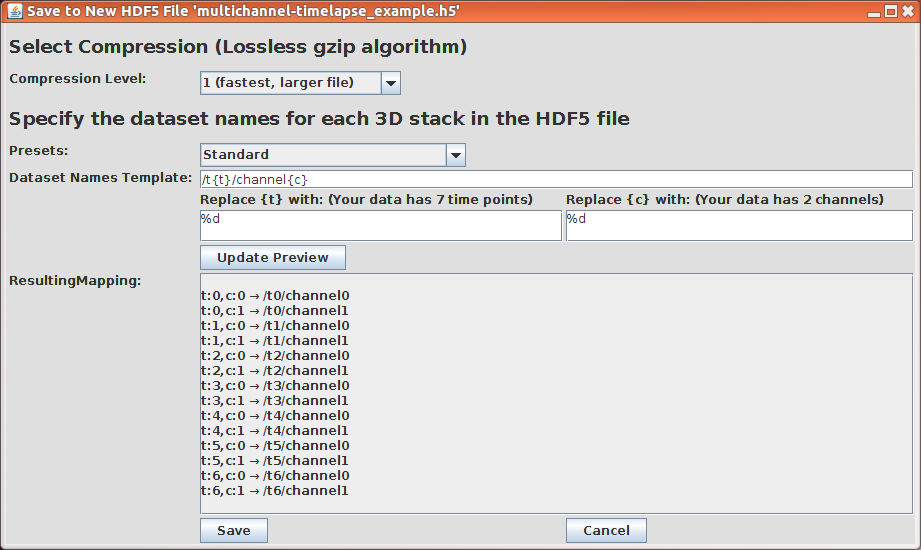
- Compression Level allow to select the compression of the data set. The compression is lossless, i.e. it works like a zip-archive. Possible compression levels are
- no compression,
- 1 (fastest, larger file)
- 2
- ...
- 9 (slowest, smallest file)
- Presets: allows to select presets for the data set layout. There is no official standard, how to name the datasets. For general purpose data we usually name it as "/t0/channel0", "t0/channel1", ... which is the "Standard" Preset.
- Dataset Names Template specifies the template string for the data set names. The placeholders {t} and {c}> will be replaced for each timepoint/channel combination with the strings specified in the following two textfields.
- Replace {t} with: and Replace {c} with: specifies the enconding of time points and channels in the filename. Possible entries area printf-style format string or a list of strings (one entry per line), e.g.,
- %d for number style like 1,2,3,...
- %.03d for zero-padded-numbers with 3 digits: 001, 002, 003, ...
- nuclei
cellborder
pattern for named channels
- The Update Preview button shows the Resulting Mapping: of the hyperstack time points and channels to the HDF5 data set names
Internals
The HDF5 plugin saves and loads the pixel/voxel size in micrometer of the image in the attribute "element_size_um". It has always 3 components in the order z,y,x (accordingly to the c-style indexing). Other meta data is not saved/loaded
Source Code
The source Code is included in the .jar-File. Just use unzip to extract it.
Wish list for next version
- Support for single data sets with more than 2GB size (will require a slice-wise or block-wise loadin/saving)
- disable the Log Window
- load a sub cube of the data set (e.g. for large 5D arrays stored in a single dataset)
Other versions
See here for much older versions of this plugin.
Contact, Bug reports and Questions
We are always interested in bug reports and feedback. Please contact us via email to Olaf Ronneberger.
Olaf Ronneberger 26.8.2014