

Deep Learning
Our group works intensively on deep learning. This includes new, untypical network architectures, new application domains, and ways to train such networks with less supervision. Some highlights of our research are shown here.

IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
We developed a network that, for the first time, allows end-to-end learning of two-frame structure from motion. The network takes two frames as input and yields the depth map and the camera motion between the two frames. In contrast to classical structure from motion techniques, the network falls back to single-image cues if the camera does not move.

IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
The improvement of our earlier FlowNet yields state-of-the-art accuracy while being orders of magnitude faster than competing optical flow methods. FlowNet 2.0 puts special emphasize on the synthesized data used for training and uses stacking of multiple networks to refine the optical flow computed at earlier stages.

Advances in Neural Information Processing Systems (NIPS), 2016
Image-generating machine learning models are typically trained with loss functions based on distance in the image space.
This often leads to over-smoothed results.
We propose to measure distances in feature spaces, and use adversarial training for keeping images realistic.
This metric better reflects perceptually similarity of images and thus leads to better results.
We show three applications: autoencoder training, a modification of a variational autoencoder, and inversion of deep convolutional networks.

IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
We propose to invert image representations with an up-convolutional neural network.
This yields insight into invariance properties of representations.
For shallow representations (HOG, SIFT, LBP) our approach provides significantly better reconstructions than existing methods, revealing that there is surprisingly rich information contained in these features.
Colors and the rough contours of an image can be reconstructed from activations in higher layers of the AlexNet network and even from the predicted class probabilities.

IEEE International Conference on Robotics and Automation (ICRA), 2016
Human body part segmentation has important applications in robotics, such as learning from demonstration and human-robot handovers.
We present a convolutional network architecture that takes as input an RGB image and assigns each pixel to one of a predefined set of human body part classes, such as head, torso, arms, legs.
Relying only on RGB rather than RGB-D images allows us to apply the approach outdoors.
The network achieves state-of-the-art performance on the PASCAL Parts dataset.
European Conference on Computer Vision (ECCV), 2016
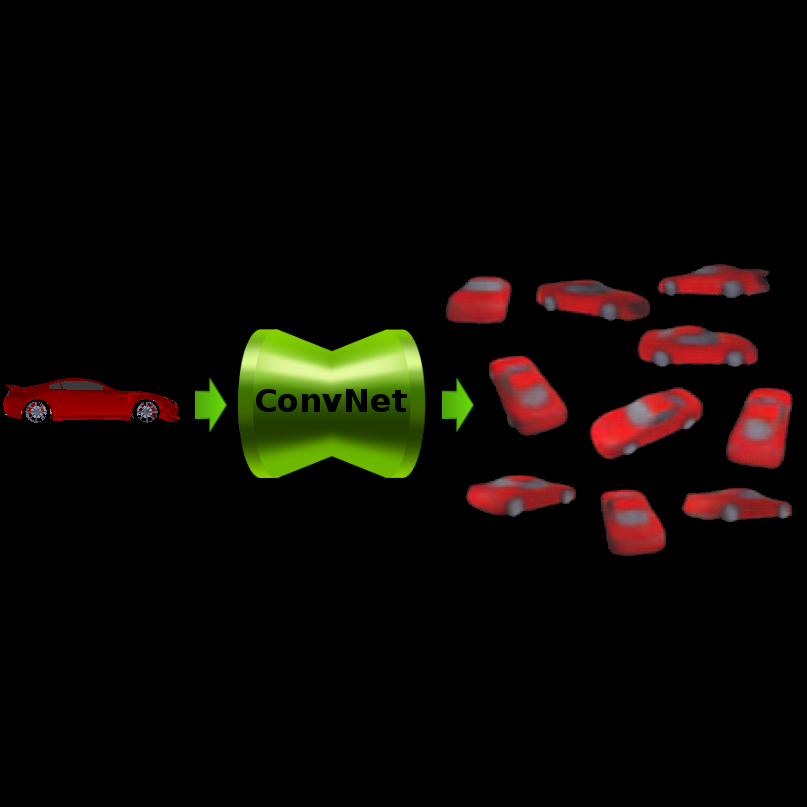
Infering a 3D model of an object from a single image of this object is a very difficult task.
We present a convolutional network capable of doing this.
The network predicts RGB images and depth maps of unseen views of an object given a single image of this object.
We train on renderings of synthetic 3D models (cars and chairs), but the network generalizes to natural images.

IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
Inspired by the success of FlowNet, we apply convolutional networks to disparity and scene flow estimation.
To this end, we create three large synthetic stereo video datasets.
With these data we train a convolutional network for real-time disparity estimation that provides state-of-the-art results.
By combining a flow and disparity estimation network and training jointly, we demonstrate the first scene flow estimation with a convolutional network.
IEEE International Conference on Computer Vision (ICCV), 2015.
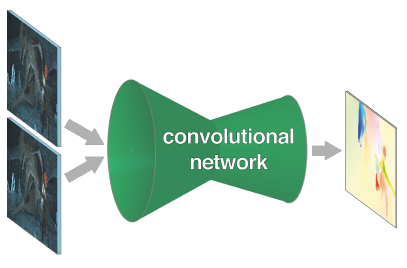
In this paper we construct CNNs which are capable of solving the optical flow estimation problem as a supervised learning task. We propose and compare two architectures: a generic architecture and another one including a layer that correlates feature vectors at different image locations. Our networks achieve competitive accuracy on Sintel and KITTI datasets at frame rates of 5 to 10 fps.
IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2015.
Neural networks cannot only classify images; they can also learn to generate images given class and viewpoint labels. Interestingly, the network can learn to predict a detailed, high-dimensional output from an abstract, low-dimensional input, which turns around the typical architecture of neural networks.


IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016.
In contrast to previous attempts to unsupervised feature learning, we propose a discriminative objective that is optimized with the typical network architecture for supervised learning. Rather than classes that would require manual annotation, we have surrogate classes, the labels of which are generated automatically. We call the network Exemplar CNN, since each surrogate class is based on a single exemplar of a training image. The features learned by this network are invariant to selected transformations and outperform features obtained with all previous unsupervised learning techniques as well as classical SIFT.
Demo video with generated chair images
|
Demo video of FlowNets
|