Contrastive Representation Learning for Hand Shape Estimation
Abstract
This work presents improvements in monocular hand shape estimation by building on top of recent advances in unsupervised learning. We extend momentum contrastive learning and contribute a structured collection of hand images, well suited for visual representation learning, which we call HanCo. We find that the representation learned by established contrastive learning methods can be improved significantly by exploiting advanced background removal techniques and multi-view information. These allow us to generate more diverse instance pairs than those obtained by augmentations commonly used in exemplar based approaches. Our method leads to a more suitable representation for the hand shape estimation task and shows a 4.7% reduction in mesh error and a 3.6% improvement in F-score compared to an ImageNet pretrained baseline. We make our benchmark dataset publicly available, to encourage further research into this direction.
HanCo Dataset
| Background Randomization | Time Sequences | Multiple Views |
|---|---|---|

|
|

|
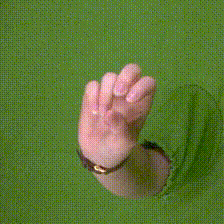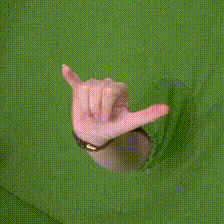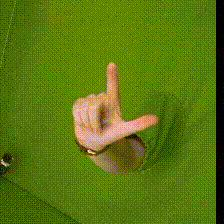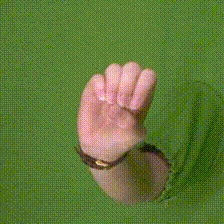
| The data was captured against a green-screen background, which allows for simple foreground detection and exchanging of the background. | HanCo was captured in short video sequences. | The dataset is captured with multiple calibrated and time synchronized cameras. In this video all cameras are iterated for a fixed time step. Three time steps are shown after each other. |
References
C. Zimmermann, M. Argus, and T. Brox, “Contrastive Representation Learning for Hand Shape Estimation“, GCPR 2021. [BibTex]