 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
SVM-Wettbewerbe
Als Praxisanteil am Seminar
Mustererkennung mit Support-Vektor-Maschinen (SVM) im WS
01/02 und WS 02/03 sind einige Wettbewerbe entstanden, die
nicht nur auf diese Veranstaltung begrenzt sind. Es werden
jederzeit Lösungen auch von nicht-Seminarteilnehmern
angenommen. Die besten Resultate werden auf dieser Seite
aktuell gehalten.
Von den Seminarteilnehmern wird eine
Bearbeitung der ersten und einer der beiden komplexeren
übrigen Aufgaben erwartet. Die verschiedenen
Implementationen werden am Semesterende gegeneinander evaluiert
bzgl. Erkennungsleistung auf vorher unbekannten
Testdatensätzen.
Aufgabe 1: SVM-Training
Problemstellung: Um etwas Übung im Umgang mit SVM zu bekommen, soll eine abstrakte Aufgabe mit Support Vektor Maschinen gelöst werden. Gegeben werden ein Lerndatensatz aus vektoriellen Daten zu einem 3-Klassenproblem in ASCII-Format. Es soll ein Programm geschrieben werden, das aus diesen Daten versucht, deren Regularität bestmöglich zu erfassen, und Klassifikationen durchführen kann. Das Format der Daten ist denkbar einfach: Jede Zeile repräsentiert ein Lern-Beispiel, d.h. eine Klassennummer 1-3 mit folgenden 64 Fliesskommazahlen, die den Beispielvektor darstellen. Es sollen Experimente mit verschiedenen Kernen, verschiedenen Trainings- und Kernparametern durchgeführt und dokumentiert werden. Hieraus können Erkenntnisse über Einfluß dieser Komponenten gewonnen bzw. bestätigt werden
Spezifikation des Klassifikators: Das Endprogramm soll ein unter Windows, SGI-Irix oder Linux ausführbares Programm sein, das eine Datei mit analoger Struktur des Lerndatensatzes als Eingabe bekommt, (die Klassennummern werden allesamt unbekannt==0 sein) und eine Liste von erkannten Klassen ausgibt. Die Eingabe in das Programm soll über die Standardeingabe der Shell erfolgen, die Ausgabe entsprechend auf die Standardausgabe. Mögliche Aufrufe eines solchen Programms myclassifier sollen folgende sein:
cat testfile.vec | ./myclassifier
cat testfile.vec | ./myclassifier > results.txt
In diesen beiden Beispielen wird eine Daten-Datei nach stdout geschrieben, dies als Standardeingabe des Klassifikators genommen. Im ersten Fall geschieht die Ausgabe der erkannten Klassen einfach in die Shell, im zweiten Fall wird sie in eine Ergebisdatei umgelenkt und ermöglicht so spätere Auswertung der Klassifikationsergebnisse.
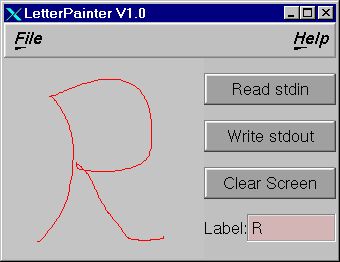
Problemstellung: Erzeugt wurde ein Datensatz von handgeschriebenen Groß-Buchstaben. Dieser wurde zufällig in zwei Teilmengen zerlegt, die eine hiervon als Lerndatensatz deklariert, die zweite wird als spätere Testbasis zurückgehalten. Der Lerndatensatz wird den Teilnehmern zur Verfügung gestellt. Auf Basis dieses 'Rohmaterials' ist jeweils ein Programm zu schreiben, das nach einem spezifizierten Ein- und Ausgabe-Schema neue Buchstaben klassifizieren kann. Durch Kopplung einer zur Verfügung gestellten 'Eingabe'-GUI mit den jeweiligen Lösungsimplementationen entsteht am Ende ein vorführbarer Buchstabenerkenner.
Durch zusätzliche Datengeneration, beliebig intelligente Vorverarbeitung des Rohmaterials, oder beliebig ausgeklügelten Klassifikator bestehen zahlreiche Möglichkeiten, den eigenen Klassifikator problemspezifisch zu optimieren. Die Wahl von Support-Vektor-Maschinen ist sehr erfolgversprechend, andere Klassifikatoren sind jedoch auch erlaubt. Implementationen von SVM stehen zur Verfügung.
Spezifikation des Klassifikators: Das Endprogramm soll wieder ein unter Windows, SGI-Irix oder Linux ausführbares Programm sein, das Beschreibungen einer Reihe zu klassifizierender Großbuchstaben im unten definierten ASCII-Format übergeben bekommt, und die erkannten Zeichen 'A' bis 'Z' ausgibt. Die Eingabe in das Programm soll über die Standardeingabe der Shell erfolgen, die Ausgabe entsprechend auf die Standardausgabe. Mögliche Aufrufe eines solchen Programms myclassifier sollen zum einen die unter Aufgabe 1 angeführten Varianten umfassen, andererseits jedoch auch Koppelung mit vor-, bzw. hintergeschalteten Programmen ermöglichen:
cat zeichenliste.acd | ./myclassifier
cat zeichen1.acd zeichen2.acd | ./myclassifier > results.txt
letterpainter | ./myclassifier | ./output_result
Im letzten Fall wird ein zur Verfügung gestelltes Editierprogramm mit dem Klassifikator gekoppelt, wodurch eine Online-Demo zur Buchstabenklassifikation entsteht. Selbstverständlich kann noch ein weiteres Programm in die Sequenz angehängt werden, welches kompliziertere Ausgabe-Operationen der einkommenden Buchstabensequenz durchführt, z.B. Darstellung eines Fensters mit eingeblendetem Buchstaben, Sprachausgabe des Zeichens etc. Hierzu ist eine Spezifikation der Ausgabe des Klassifikators notwendig: Es soll pro klassifiziertes Sample der geschätzte Großbuchstabe nach stdout ausgegeben werden.
Diese Datentransfermethode wurde gewählt, um möglichst viel Freiheit in der Wahl der Programmiersprache zu gestatten und gleichzeitig "Modularität" zu erreichen, wie durch die drei Beispiele illustriert wird.
Datenformat: Für die kompakte Darstellung eines handgeschriebenen Zeichens bietet sich eine Codierung basierend auf den Streckenzügen des Zeichens an. Eine einfache ASCII-basierte Auflistung dieser Streckenzüge soll als Datenformat dienen. Eine detailliertere Beschreibung des ACD-Formats (ASCII-Character-Description) mit Beispielen steht zur Verfügung.
Bisherige Resultate:
| Rang | Testfehlerrate | Teilnehmer | Datum |
| 1. | 1.43% | Bhaskara Reddy Poluru | 25.3.2003 |
| 2. | 1.68% | Claus Bahlmann | 4.3.2002 |
| 3. | 2.94% | Nicolai Mallig | 14.2.2002 |
| 4. | 3.22% | Niels Landwehr | 13.2.2002 |
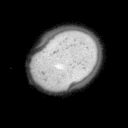
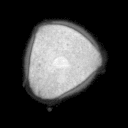
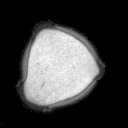
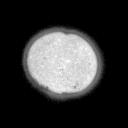
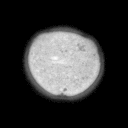
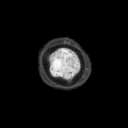
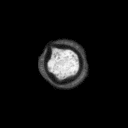
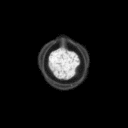
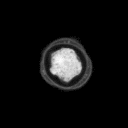
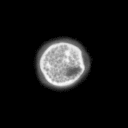
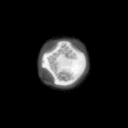
Problemstellung: Erzeugt wurde ein
Datensatz aus Mikroskopaufnahmen von Blütenpollen. Die
unterschiedlich großen Bilder liegen im PGM-Bildformat
vor. Pro Probe wurde ein Durchlicht- und Fluoreszenzbild aufgenommen,
deren Pixel korrespondieren.
Dieser Datensatz wurde zufällig in zwei Teilmengen zerlegt, die
eine hiervon als Lerndatensatz deklariert, die zweite wird als
spätere Testbasis zurückgehalten. Der Lerndatensatz
wird den Teilnehmern zur Verfügung gestellt. Auf Basis
dieses 'Rohmaterials' ist jeweils ein Programm zu schreiben,
das nach einem spezifizierten Ein- und Ausgabe-Schema neue
Pollenbilder klassifizieren kann.
Die Trainingsbilder haben folgende
Struktur: obj_fl_01932_0_tr.pgm
Die Fünfstellige Nummer ist der Index der Probe, anschließend folgt die
1 oder 2-stellige Klassennummer (0 = kein Pollen,3 = Erle (Alnus),7 = Hasel (Corylus), 33 = Taxus (Eibe) ), hierauf folgt ein Kürzel für Durchlicht-
(tr) oder Fluoreszenzaufnahme (fl).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Durch zusätzliche Datengeneration, beliebig intelligente Vorverarbeitung des Rohmaterials, oder beliebig ausgeklügelten Klassifikator bestehen zahlreiche Möglichkeiten, den eigenen Klassifikator problemspezifisch zu optimieren. Die Wahl von Support-Vektor-Maschinen ist sehr erfolgversprechend, andere Klassifikatoren sind jedoch auch erlaubt. Implementationen von SVM stehen zur Verfügung.
Spezifikation des Klassifikators: Das Endprogramm soll wieder ein unter Windows, SGI-Irix oder Linux ausführbares Programm sein, das als Kommandozeilenparameter einen Verzeichnisnamen übergeben bekommt, und die hierin liegenden PGM-Bildpaare (*_tr.pgm und *_fl.pgm) alphabetisch sortiert klassifiziert. Die Ausgabe soll in die Standardausgabe der Shell erfolgen und jeweils zeilenweise die Bezeichnung einer Probe (Bildname ohne _tr.pgm) gefolgt von dem Code der geschätzten Pollensorte enthalten. Mögliche Aufrufe eines solchen Programms myclassifier sollen zum Beispiel folgende umfassen:
./myclassifier ../sample_dir
./myclassifier sample_dir > results.txt
Durch diese Spezifikation ist freie Wahl der Programmiersprache möglich.
Datenformat: Die Bilder der Pollen liegen im einfach handhabbaren PGM-Format vor. Eine genaue Spezifikation dieses Formats ist z.B. über die Linux-Manpages (man pgm) oder in zahlreichen Quellen im Internet einsehbar.
Bisherige Resultate:
| Rang | Testfehlerrate | Teilnehmer | Datum |
| 1. | 2.94% | Klaus Peschke | 24.3.2003 |
| 2. | 4.56% | Thorsten Schmidt | 14.2.2003 |
| 3. | 6.77% | Janis Fehr | 14.2.2003 |
Programmiersprache: Die Wahl der Programmiersprache ist frei, solange sie Standardeingabe aus der Shell und Standardausgabe in die Shell nach angegebener Spezifikation erlaubt, und die Programme via Kommandozeile aufrufbar sind. Die Plattform sollte entweder Windows, SGI-Irix oder Linux sein.
Software:
Abgabe: Abgabe der Programme zwecks Lauffähigkeit/Vorabtest der Implementationen bitte bis Ende der vorletzten Vorlesungswoche beim Betreuer. In der letzten Seminarsitzung werden die Implementationen von den Teilnehmern kurz vorgestellt und anschließend ihre Erkennungsleistung auf unbekannten Testdatensätzen gegeneinander verglichen.
Betreuer: Bernard Haasdonk
Email: haasdonk@informatik.uni-freiburg.de
WWW:
www.informatik.uni-freiburg.de/~lmb/
Telefon: 203 8274 oder -8260 (Sekr.)